7. 多线程¶
我们先来看一个熟悉的例子。
在下图中,包含了 6 个 Action :
首先, US 会执行异步操作 Action1 ,以等待一个请求消息;
随后, Action2 和 Action3 是两个并发进行的异步操作;
在 Action2 和 Action3 完成之后, Action4 和 Action5 同样是两个异步操作, 会依次顺序执行;
最后,执行同步操作 Action6 ,以回复一个响应消息。
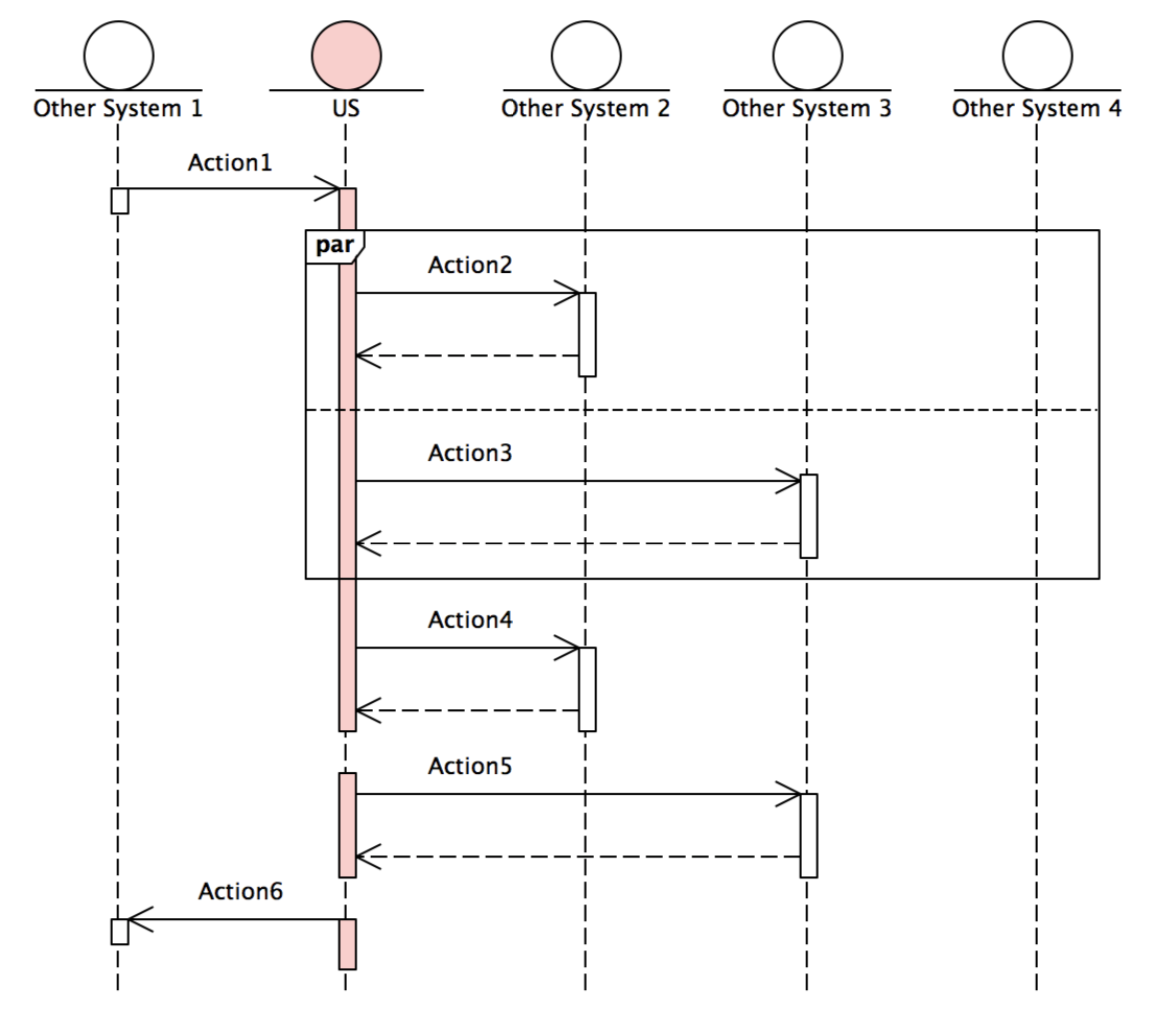
这个过程简单而清晰,我们可以轻易的使用 Transaction DSL 对其进行描述。
__transaction
( __req(Action1)
, __concurrent(__asyn(Action2), __asyn(Action3)) , __asyn(Action4)
, __asyn(Action5)
, __rsp(Action6)));
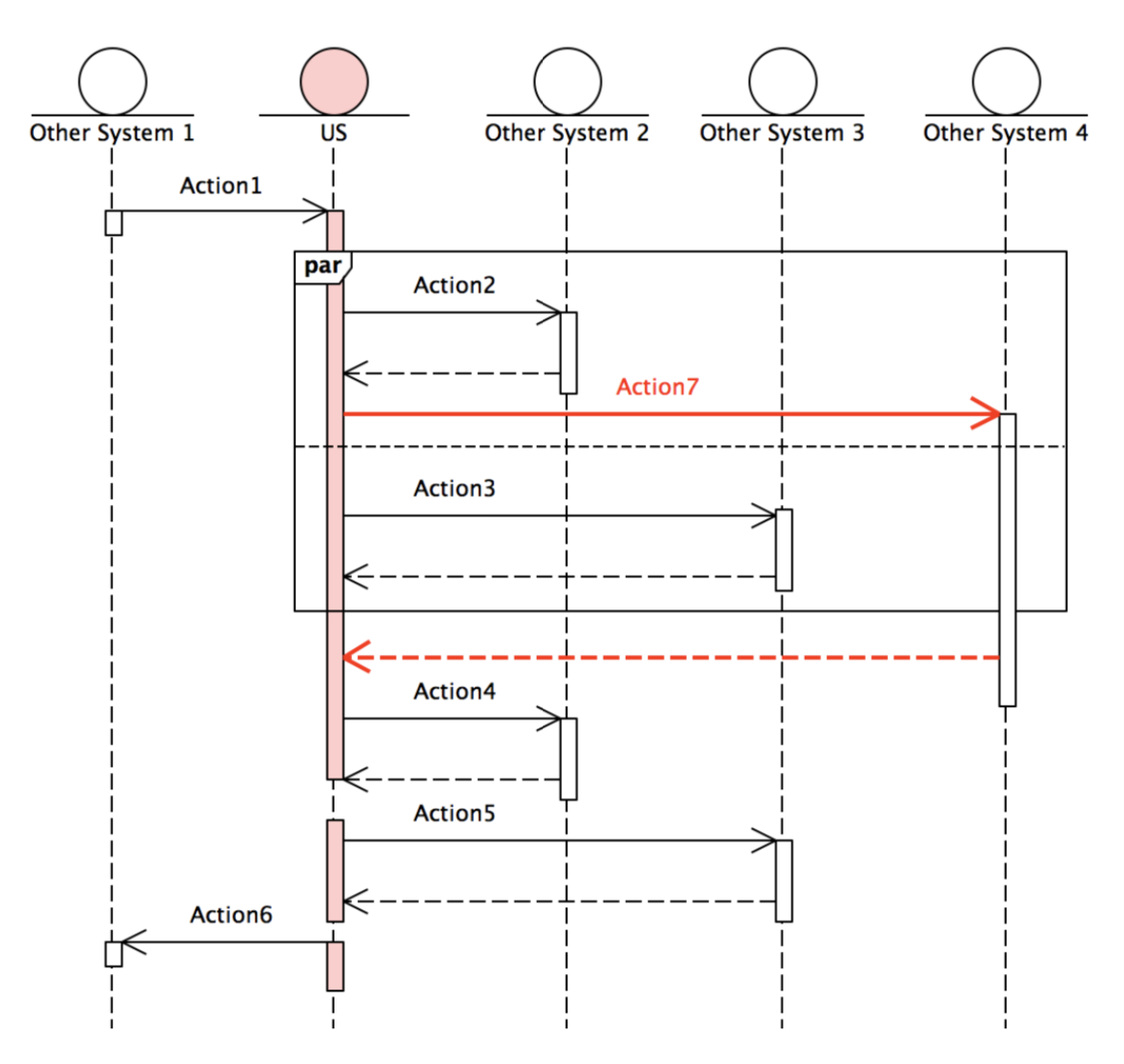
但事情并非总是这么简单。如下图所示,有一天,需求迫使你不得不在原有流程上加入一个新的异步处理: 在 Action2 收到其应答消息之后,需要马上发出一条新消息,但却无须停下来等待其应答,整个流程仍然按照原有的方式往前走。 在这期间,应答消息随时可能到来。一旦其收到这条应答,系统应该马上对其进行处理。
而这个新增的请求-应答异步操作,就是下图中的 Action7 :
这样的过程,用 序列图 可能不能准确的表达其过程,而 活动图 会让其更加直观:
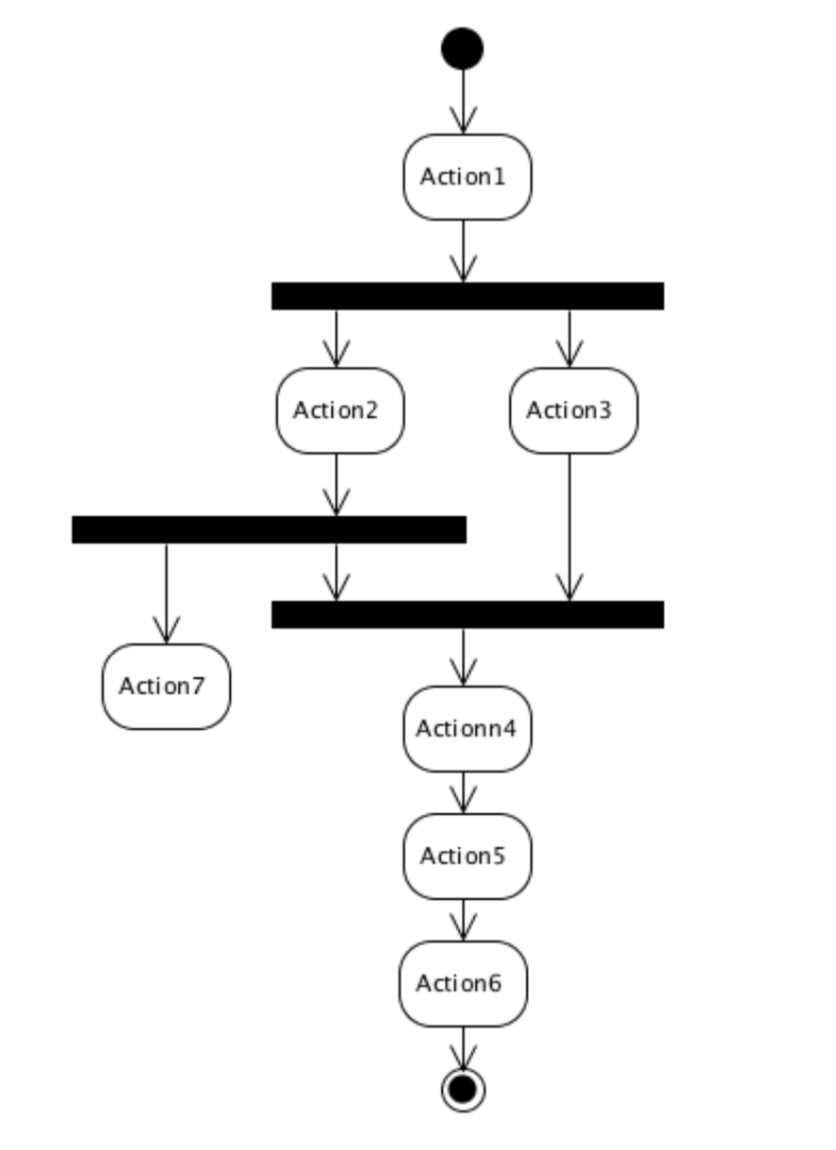
7.1. __fork¶
上图已经揭示了问题的本质:新加入的 Action7 已经脱离了本来的控制序列,独自形成了另外一条控制序列。如果我们将一条控制序列看作一个线程, 那么,我们已经在面对多线程的问题。
在 Transaction DSL 中,我们可以使用 __fork 来创建一条新线程。例如:
const ActionThreadId ACTION7_THREAD = 1;
__fork(ACTION7_THREAD, __asyn(Action7))
正如例子所揭示的, __fork 有两个参数:
第一个参数是 Thread ID ,随后我们会谈到。
第二个参数则是在这条线程上执行的操作。在一条线程的执行的操作,在本例中非常简单; 但事实上,它可以是任意复杂的操作,比如:
__fork(THREAD1, __sequential
( __concurrent(__asyn(Action1), __asyn(Action2)) , __asyn(Action2)
, __time_guard(TIMER2, __asyn(Action3)))
而对于我们这个例子,其完整的描述如下:
const ActionThreadId ACTION7_THREAD = 1;
__transaction
( __req(Action1)
, __concurrent
( __sequential
( __asyn(Action2)
, __fork(ACTION7_THREAD, __asyn(Action7)))
, __asyn(Action3))
, __asyn(Action4)
, __asyn(Action5)
, __rsp(Action6));
其中,我们将 Action2 和 ACTION7_THREAD 放在了一个 __sequential 操作里。
这是因为,我们必须确保,ACTION7_THREAD 的创建发生在 Action2 的成功执行结束之后。
同时,我们也必须确保,这个序列,和 Action3 是并行发生的。
7.1.1. 此线程非彼线程¶
尽管 Transaction DSL 引入了线程的概念,但这里的线程与操作系统或任何平 台所提供的线程之间没有任何关系。 它是一个由事务框架创建,管理和调度的实体,操作系统或平台完全意识不到它们的存在。
其执行和调度粒度是以 Action 为单位的,不像操作系统级别的线程是以硬件指令为单位的。 在一个抢占式的系统中,操作系统级别的线程,可以在允许的任何指令处暂停或中止一个线程的运行, 但 Transaction DSL 的线程则完全做不到这一点, 当然,它也没有任何必要去做到这一点。
所以,在 Transaction DSL 里,其准确的名字是操作线程 (Action Thread)。
7.2. __join¶
当创建了一条线程时,它就和其它的线程——包括主线程——各自独立的并发执行,互不干扰,老死不相往来。
但是,在现实的系统中,往往又存在这这样的需求,即,虽然同时存在多个线程,但其中某个线程的执行过程中,某个步骤的后续执行, 是以另外一条线程的执行结束为前提的。
比如,我们可以给之前的例子增加一个约束: Action5 开始执行之前,要求 Action7 必须执行完毕。如图所示:
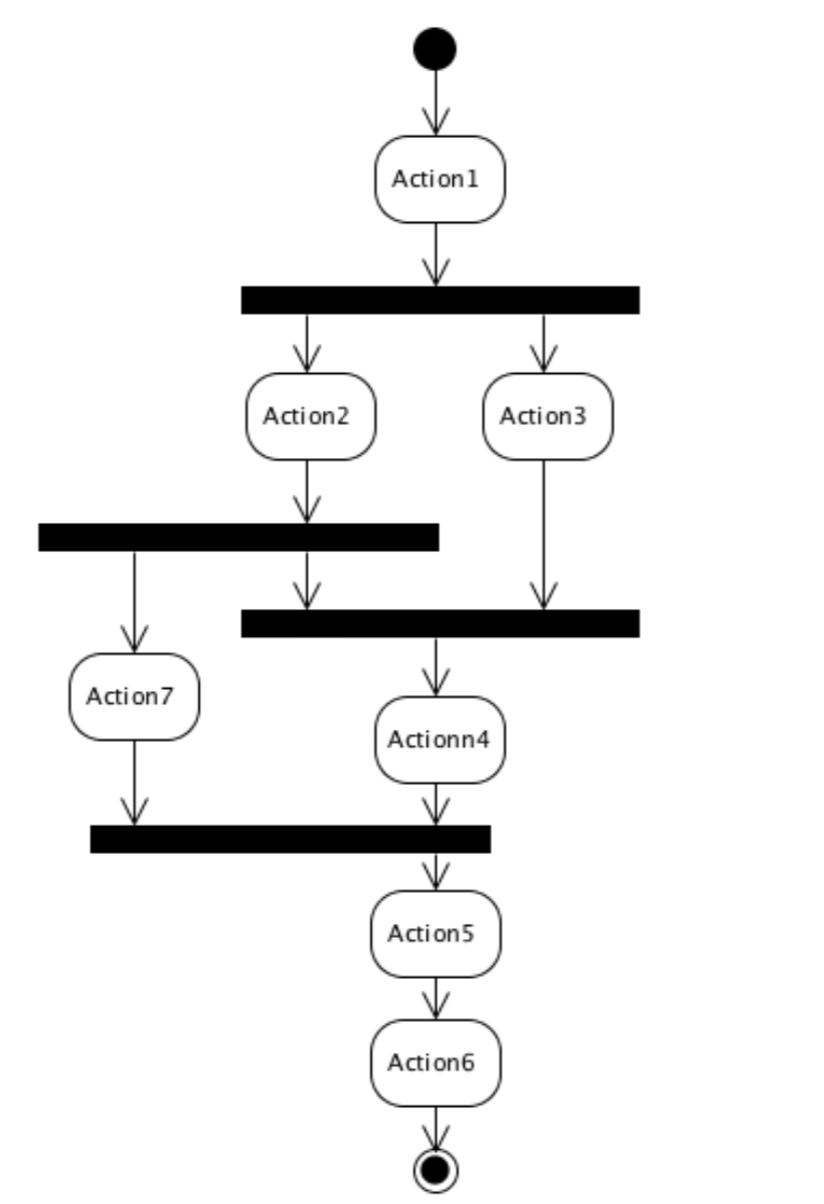
对于这样的约束,你可以使用 __join 来描述。它的参数,就是某个线程要等待的 Thread ID 。例如:
// ...
__fork(THREAD1, __asyn(Action1))
// ...
__join(THREAD1)
// ...
将其应用于我们的例子,其完整的描述如下:
const ActionThreadId ACTION7_THREAD = 1;
__transaction
( __req(Action1)
, __concurrent
( __sequential
( __asyn(Action2)
, __fork(ACTION7_THREAD, __asyn(Action7)))
, __asyn(Action3))
, __asyn(Action4)
, __join(ACTION7_THREAD)
, __asyn(Action5)
, __rsp(Action6));
在 __join 时,如果被 join 的线程已经执行完毕,则 __join 马上完成。否则, __join 所在线程
将在 __join 处一直等待,直到目标线程运行结束。
如果一个线程 __join 它自己,会马上成功完成。
7.2.1. Thread ID¶
Thread ID ,标示了一个线程的身份,所以,在一个事务中,每个线程的 Thread ID 必须唯一。
在目前的实现中,其取值范围为 0 到 7 ,但 0 是主线程的 ID ,用户不能使用。所以,在一个事务中,用户最多允许创建 7 个线程。
由于 __join 机制的存在,在 __join 时,用户必须有一种手段,来指明具体的线程。所以,每个线程必须有一个唯一的身份标识。
从实现手段上,这个标识可以是一个字符串,从而避免让用户需要亲自来分配和管理 Thread ID 。
但是,从语言的约束和实现的复杂度上,用整数作为标识,是最为简单的。虽然这略微增加了用户的负担,
但却避免了框架实现的复杂度。毕竟,用户最多只能在一个事务中创建 7 个线程,这仍然在人类可轻松管理的范围内。
7.2.2. 同时等待多个线程¶
有些时候,一个线程的继续执行,是以多个线程的执行结束为条件的。这种情况下,你仍然使用 __join 。
比如,在下图中所描述的事务中,Action2 和 Action3 在执行结束后,分别启动了一个线程,
并发的运行 Action7 和 Action8 ,随后,在执行 Action5 之前,要求这两个线程都必须执行结束。
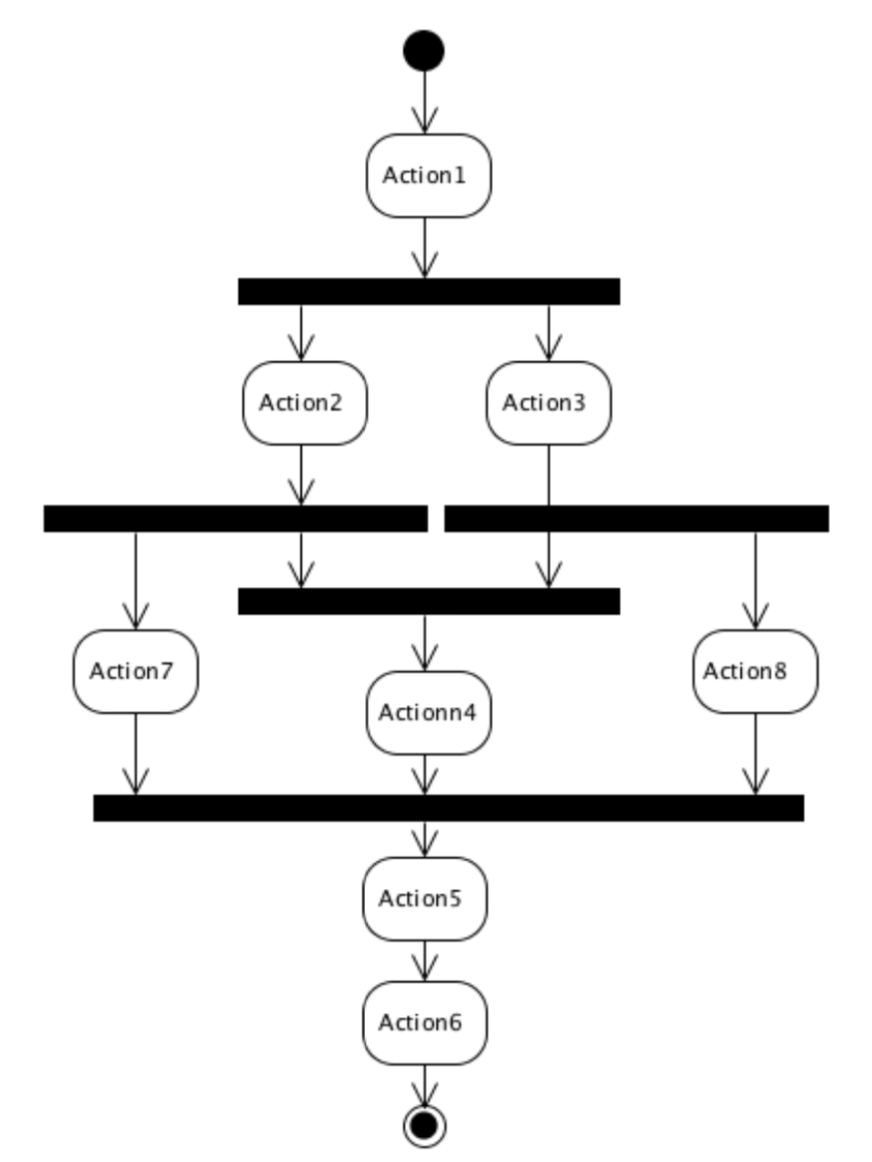
可描述为:
const ActionThreadId ACTION7_THREAD = 1;
const ActionThreadId ACTION8_THREAD = 2;
__transaction
( __req(Action1)
, __concurrent
( __sequential
( __asyn(Action2)
, __fork(ACTION7_THREAD, __asyn(Action7)))
, __sequential
( __asyn(Action3)
, __fork(ACTION8_THREAD, __asyn(Action8))))
, __asyn(Action4)
, __join(ACTION7_THREAD, ACTION8_THREAD) , __asyn(Action5)
, __rsp(Action6));
__join 是一个变参操作,最多可以等待 7 个线程。因为每个事务的最大线程数量是 8 个。所以,每个线程都可以等待所有其它线程。
或许你会敏锐的发现,对于下图所描述的事务,和上图中所描述的事务是等价的。
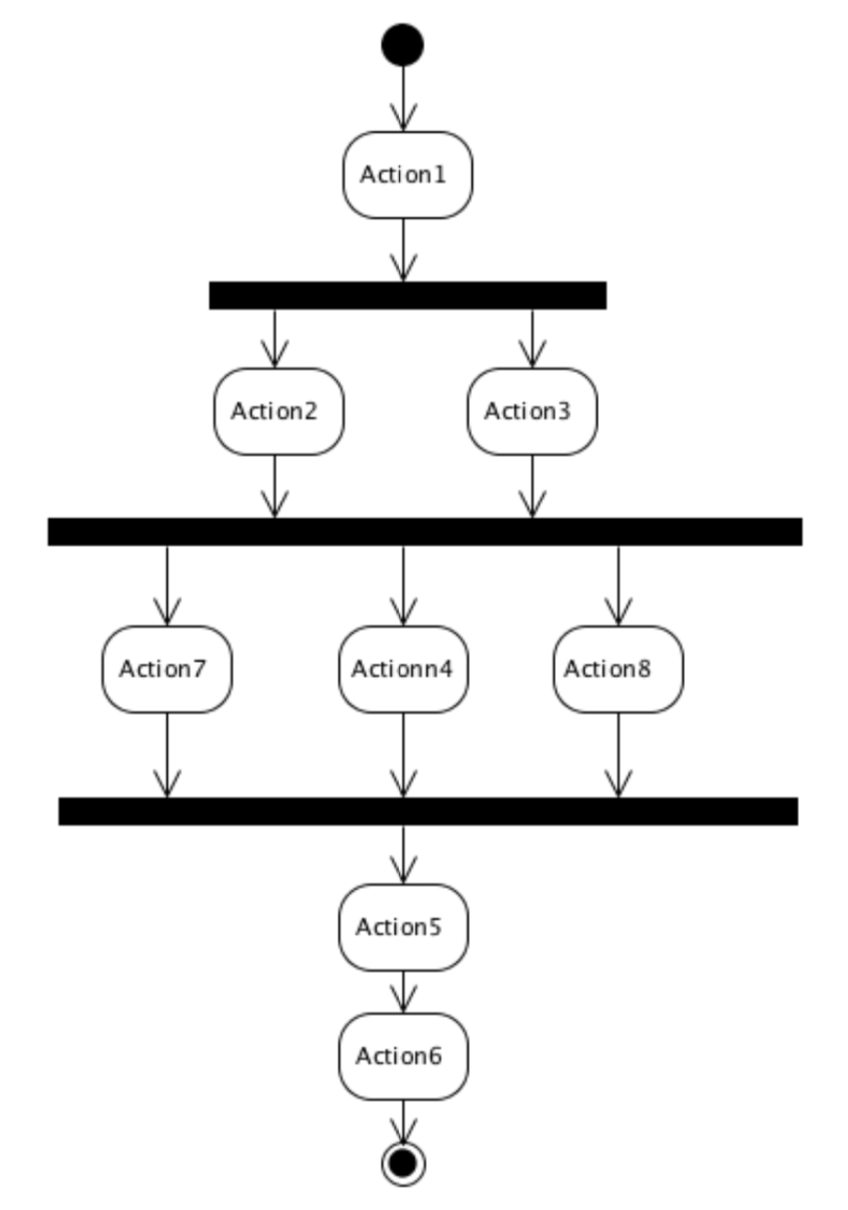
所以,你会希望将代码写成这种形式,从而减少对于线程的操作,也让代码看来更加的简洁。
__transaction
( __req(Action1)
, __concurrent(__asyn(Action2), __asyn(Action3))
, __concurrent(__asyn(Action7), __asyn(Action4), __asyn(Action8))
, __asyn(Action5)
, __rsp(Action6));
不幸的是,尽管它们看起来很相似,但它们的实时性和性能却并不相同(想像一下, Action2 和 Action8 是慢速操作,
而 Action3 和 Action7 是快速操作,对比一下两者的性能)。而对于实时性和性能的追求,正是我们使用并发模型的原因,
不是吗?
7.2.3. 匿名线程¶
你应该早就已经意识到,在 __concurrent 里的多个操作,和通过 __fork 创建线程执行的操作都是并发操作。
所以, __concurrent 里的每个 Action 也都是线程。
不同的是,它们没有自己明确的身份: Thread ID 。所以,直接被放在 __concurrent 里的线程被称为匿名线程。
之所以它们不需要 Thread ID ,是因为 __concurrent 本身已经保证了这些线程 会被自动的 __join , 比如:
__concurrent(__asyn(Action1), __asyn(Action2))
从控制过程看,就近似的等价于:
__fork(TID1, __asyn(Action1)),
__fork(TID2, __asyn(Action2)),
__join(TID1, TID2)
但很明显,前一种写法更加简单明确。另外,匿名线程的一个重要优势是:没有数量上的约束。在一个事务内部,你可以根据需要创建任意多个匿名线程。 其实,匿名线程和有名线程之间的差别还有很多,我们会在其它相关的部分进行讨论。
7.3. 调度策略¶
对于一个事务而言,即便存在多条线程,但只要主线程执行结束,整个事务就执行结束。此时,其它线程执行到什么阶段,
都不会影响一个事务的 exec 或 handleEvent 函数的返回值(你应该还记得,其返回值为 CONTINUE 表示一个事务仍在工作,
而 SUCCESS 则表示其已经成功结束)。
当主线程结束时,所有其它正在工作的有名线程将会被强行中止。 所以,一个用户创建的有名线程 __join 主线程是没有意义的。
7.3.1. join all¶
如果你期望所有的线程都结束之后,整个事务才能结束,那么你应该在主线程使用 __join ,但不指定任何具体 Thread ID
来等待 所有 其它线程结束。
__transaction
( __fork(THREAD1, __asyn(Action1))
, __fork(THREAD2, __asyn(Action2))
, __asyn(Action3)
, __join());
如果主线程是一个 __procedure ,那么就应该在 __finally 里 __join,比如:
__transaction
( __fork(THREAD1, __asyn(Action1))
, __fork(THREAD2, __asyn(Action2))
, __asyn(Action3))
, __finally
( __asyn(Action4)
, __join()));
注意,__join 并不关心它所等待的线程是以成功还是失败,而只关心它们是否已经结束。
7.3.2. 线程错误¶
Transaction DSL 对于错误的应对哲学是:尽早失败 ( Fail Fast )。 因为,一旦一个事务中的任何一点发生了不可修复的错误,那么就应该让整个事务的所有线程都进入失败处理。 否则,将会导致其它线程的不必要的行为浪费。
7.3.2.1. 有名线程的失败¶
如果线程启动时发生错误, __fork 以失败结束。比如在下面的过程里:
__transaction
( __fork(THREAD1, __asyn(Action1))
, __asyn(Action2))
, __finally(__on_fail(__asyn(Action3))));
如果 Action1 的 exec 调用结果为某种错误,则 __fork 失败,从而 Action2 会被调过,直接进入 __finally ;
而由于 __fork 失败,因而 __on_fail 谓词判断结果为 true ,所以, Action3 会得到执行。
一旦线程的 exec 执行结果是 SUCCESS ,则 __fork 成功。
如果被创建线程 exec 的结果是 CONTINUE , __fork 同样成功结束。而被创建线程开始独立运行,从此与创建者线程之间再无任何关系。
如果随后任何线程发生了错误,(无论是通过上下文汇报的错误,还是通过执行结果返回的错误),都将导致对所有其它线程的 stop 调用。比如:
__transaction
( __fork(THREAD1, __asyn(Action1))
, __fork(THREAD2, __asyn(Action2))
, __asyn(Action3)
, __asyn(Action4))
, __recover
( __on_fail(__asyn(Action5))
, __on_succ(__asyn(Action6))));
在 THREAD1 和 THREAD2 被成功 __fork 后,如果 Action2 在随后的处理过程中发生了错误,则主线程和``THREAD1`` 都会
被 stop ,从而导致 THREAD1 的直接终止,而主线程的 Action3 也同样被终止, 并跳过 Action4 ,
直接进入 __recover 。而由于这个错误,Action5 得到执行。由于 __recover ,整个过程最终失败还是成功,取决于 Action5 的执行结果。
但是,如果在 THREAD1 或 THREAD2 发生任何错误之前,主线程已成功进入 __recover ,由于 __recover 让主线程
处于 免疫模式 ,所以,其它线程发生的任何错误,都将无法再影响到主线程。从而也无法影响到整个事务的运行结果。
因而,如果你的确想感知其它线程的失败,则务必在进入 __finally 或 __recover 之前,进行 __join 。
7.3.2.2. 匿名线程的失败¶
而匿名线程则不然,它的错误将会被创建线程捕捉到。如果发生错误的匿名线程处于其创建线程的
某个 __procedure 内,则这个错误将可能被 __procedure 的 __recover 捕捉并修复。
比如,在下面的事务中,如果 Action1 发生失败,它将会中止 Action2 的执行,
然后转向执行 Action4 ,如果 Action4 成功执行,则整个事务则成功结束。
__transaction
( __concurrent
( __asyn(Action1)
, __asyn(Action2))
, __asyn(Action3)
, __recover(__asyn(Action4)))
另外,当一个匿名线程失败后,其宿主有名线程必须等待匿名线程所处的整个 __concurrent 执行结束之后,才能进入 __finally 操作。
比如在下面的事务中,如果 Action1 失败,它所在的匿名线程将会马上以失败结束。
由于其所处的 __concurrent 里,还存在另外一条匿名线程,所以,另外一条匿名线程也会进入失败处理,
从而跳转执行 Action3 ;由于 Action3 是一个异步操作, 需要等待进一步的消息。所以,到目前为止,
整个 __concurrent 并没有执行结束。
等 Action3 等到期待的消息并处理之后, __concurrent 里的两个匿名线程都结束了,
从而导致整个 __concurrent 以错误的状态结束。
然后,其所处的 有名线程 —— 在这里是 主线程 —— 将会跳进 __finally ,去执行 Action5 ; 等 Action5 执行结束后,
整个事务将以失败结束。
__transaction
( __concurrent
( __asyn(Action1)
, __procedure(__asyn(Action2), __finally(__asyn(Action3))))
, __asyn(Action4)
, __finally(__asyn(Action5)))
尽管如此,当一个匿名线程失败时,仍然会及时的通知给整个事务,从而让事 务内的其它线程可以尽早进入失败处理。
比如,在下面的事务里,如果匿名线程的 Action2 发生了失败, THREAD1 将会马上意识到这个错误并结束执行。
而主线程的错误处理顺序则和上一个例子所描述的过程一样。
__transaction
( __fork(THREAD1, __asyn(Action1))
, __concurrent
( __asyn(Action2)
, __procedure(__asyn(Action3), __finally(__asyn(Action4))))
, __asyn(Action5)
, __recover(__asyn(Action6)))
7.3.3. __multi_thread 约束¶
创建线程时, Thread ID 一定要从 1 开始,并且连续(如果创建多个其它线程时);
主线程一旦结束,则整个
__multi_thread都将结束;而运行结果则是主线程的执行结果;其它线程不能
__join主线程;其它线程不能
__join(),即 join all ;其它线程进行
__join时,不能得到保证;